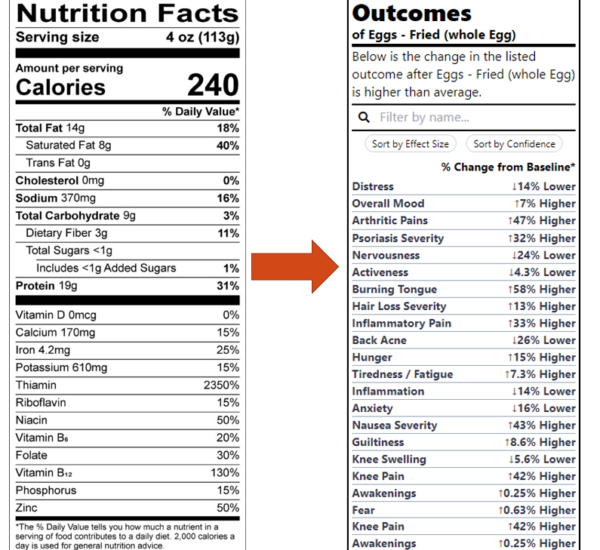
Currently, all foods carry nutrition labels such as this one:
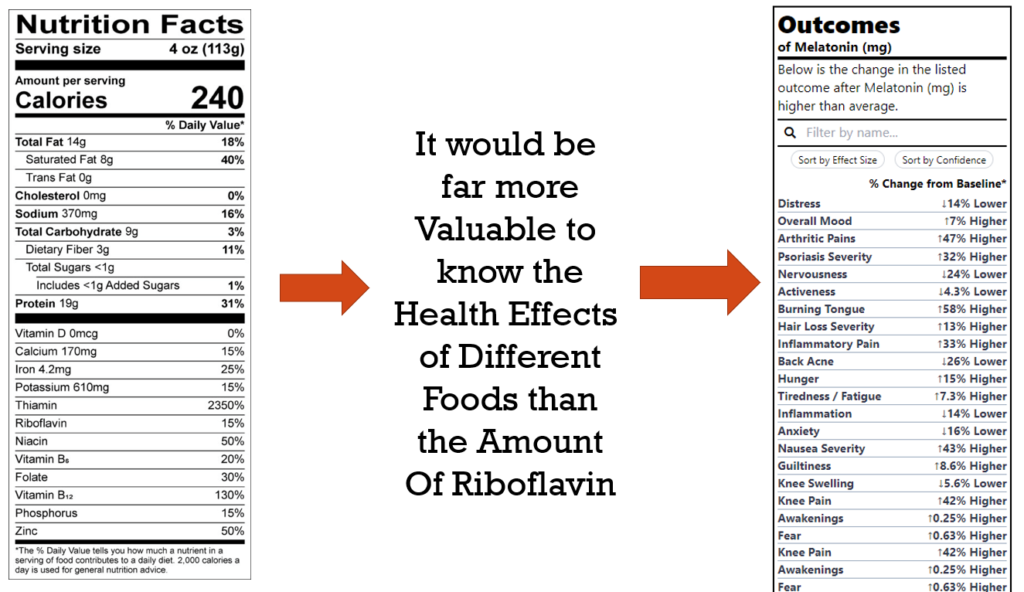
But how useful is it to the average person to know the amount of Riboflavin in something? The purpose of nutritional labels is to help individuals make choices that will improve their health and prevent disease.
Telling the average person the amount of riboflavin in something isn’t going to achieve this. This is evidenced by the fact that these labels have existed for decades and during this time, we’ve only seen increases in most diseases they were intended to reduce.
We have created a new and improved Outcomes Label that instead lists the degree to which the product is likely to improve or worsen specific health outcomes or symptoms. We currently have generated Outcome Labels for thousands of foods, drugs, and nutritional supplements that can be found at studies.crowdsourcingcures.org. These labels are derived from the analysis of 10 million data points anonymously donated by over 10,000 study participants via the app at app.crowdsourcingcures.org.
Data Quantity
The Foundation has collected over 10 million data points on symptom severity and influencing factors from over 10,000 people. The Foundation develops and applies predictive machine learning algorithms to the data to reveal effectiveness and side-effects of treatments and the degree to which hidden dietary and environmental improve or exacerbate chronic illnesses
These analytical results have been used to freely publish 90,000 studies on the effects of various treatments and food ingredients on symptom severity.

Although 10 million data points sound like a lot, currently, the usefulness and accuracy of these Outcome Labels are currently limited. This is due to the fact there are only a few study participants have donated data for a particular food paired with a particular symptom. In observational research such as this, a very large number of participants are required to cancel out all the errors and coincidences that can influence the data for a single individual.
For instance, someone with depression may have started taking an antidepressant at the same time they started seeing a therapist. Then, if their depression improves, it’s impossible to know if the improvement was a result of the antidepressant, the therapist, both, or something else. These random factors are known as confounding variables. However, random confounding factors can cancel each other out when looking at large data sets. This is why it’s important to collect as much data as possible.
Data Sources
Several types of data are used to derive the Outcome Labels:
- Individual Micro-Level Data – This could include data manually entered or imported from other devices or apps at app.crowdsourcingcures.org, This could also include shopping receipts for foods, drugs, or nutritional supplements purchased and insurance claim data.
- Macro-Level Epidemiological Data – This includes the incidence of various diseases over time combined with data on the amounts of different drugs or food additives. This is how it was initially discovered that smoking caused lung cancer. With macro-level data, it’s even harder to distinguish correlation from causation. However, different countries often enact different policies that can serve as very useful natural experiments. For instance, 30 countries have banned the use of glyphosate. If the rates of Alzheimer’s, autism, and depression declined in these countries and did not decline in the countries still using glyphosate, this would provide very powerful evidence regarding its effects. Unfortunately, there is no global database that currently provides easy access to the incidence of these conditions in various countries over time and the levels of exposure to various chemicals.
- Clinical Trial Data – This is the gold standard with regard to the level of confidence that a factor is truly the cause of an outcome. However, it’s also the most expensive to collect. As a result, clinical trials are often very small (less than 50 people). Exclusion criteria in trials often prevent study participants from being representative of real patients. There are ethical considerations that prevent us from running trials that have any risk of harm to participants. Due to the expense involved we have very few trials run on anything other than a molecule that can be patented and sold as a drug.