There are over 2 billion people suffering from chronic diseases.
Additionally, 150,000 people die every single day by possibly preventable degenerative diseases. For perspective, this is equivalent to:

deaths from disease
Will throwing more money at the existing healthcare system save us?
Since 2014, healthcare spending per person has been increasing faster than ever faster than ever before.
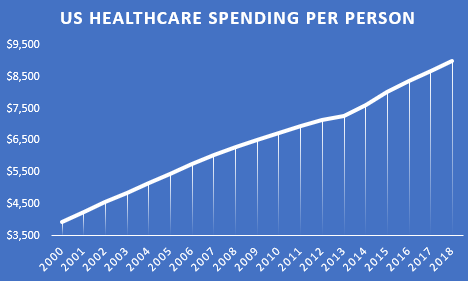
health spending
Despite this additional spending, life expectancy in the US has actually been declining over that time.
Will digital health innovation save us?
There has been an explosion of recent technological advances in digital health, including:
- genetic sequencing
- gut microbiome sequencing
- 350,000 digital health apps
- a billion connected wearable devices
These innovations have produced a 50-fold growth in the amount of data on every disease and every factor that could improve, exacerbate, or prevent it.
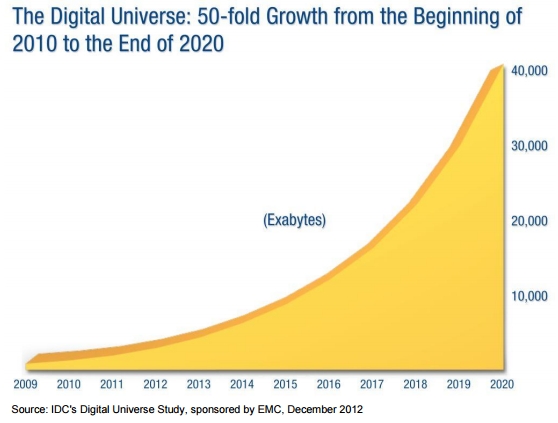
This data exists in the form of:
- Electronic Medical Records
- Genetic Sequencing
- Data from Fitness and Sleep trackers
- Data from diet and treatment tracking apps
- Health insurance claims
- Grocery, pharmacy, and nutritional supplement receipts and purchases
- Clinical trial results
The digital health revolution started over a decade ago. It was promised to improve human health and reduce costs. Yet, all we’ve seen is increasing costs, increasing disease burden, and decreasing life expectancy.
cost and death
Why haven’t we seen a reduction in disease burden?
So, this explosion in technology, data, and spending has produced no measurable improvement in human health. The reason, in a single word, is incentives. The current economic system punishes every stakeholder in the ecosystem for doing the things that would lead to progress.
1.2 Problems in Clinical Research
1.2.1 The Cost of Clinical Research
- It costs $2.6 billion to bring a drug to market (including failed attempts).
- The process takes over 10 years.
- It costs $36k per subject in Phase III clinical trials.

This high cost leads to the following problems:
No Data on Unpatentable Molecules
We still know next to nothing about the long-term effects of 99.9% of the 4 pounds of over 7,000 different synthetic or natural chemicals you consume every day.
Under the current system of research, it costs $41k per subject in Phase III clinical trials. As a result, there is not a sufficient profit incentive for anyone to research the effects of any factor besides a molecule that can be patented.

how much we know
Lack of Incentive to Discover the Full Range of Applications for Off-Patent Treatments
There are roughly 10,000 known diseases afflicting humans, most of which (approximately 95%) are classified as “orphan” (rare) diseases. The current system requires that a pharmaceutical company predict a particular condition in advance of running clinical trials. If a drug is found to be effective for other diseases after the patent has expired, no one has the financial incentive to get it approved for another disease.
No Long-Term Outcome Data
Even if there is a financial incentive to research a new drug, there is no data on the long-term outcomes of the drug. The data collection period for participants can be as short as several months. Under the current system, it’s not financially feasible to collect data on a participant for years or decades. So we have no idea if the long-term effects of a drug are worse than the initial benefits.
For instance, even after controlling for co-morbidities, the Journal of American Medicine recently found that long-term use of Benadryl and other anticholinergic medications is associated with an increased risk for dementia and Alzheimer disease.
1.2.2 Conflicts of Interest
Long-term randomized trials are extremely expensive to set up and run. When billions of dollars in losses or gains are riding on the results of a study, this will almost inevitably influence the results. For example, an analysis of beverage studies, published in the journal PLOS Medicine, found that those funded by Coca-Cola, PepsiCo, the American Beverage Association, and the sugar industry were five times more likely to find no link between sugary drinks and weight gain than studies whose authors reported no financial conflicts.
The economic survival of the pharmaceutical company is dependent on the positive outcome of the trial. While there’s not a lot of evidence to support that there’s any illegal manipulation of results, it leads to two problems:
Negative Results are Never Published
Pharmaceutical companies that sponsor research often report only “positive” results. They leave out the non-findings or negative findings. In some cases, a new drug or procedure may have proved more harmful than helpful. Selective publishing can prevent the rapid spread of beneficial treatments or interventions, but more commonly it means that bad news and failure of medical interventions go unpublished. Past analysis of clinical trials supporting new drugs approved by the FDA showed that just 43 percent of more than 900 trials on 90 new drugs ended up being published. In other words, about 60 percent of the related studies remained unpublished even five years after the FDA had approved the drugs for market. That meant physicians were prescribing the drugs and patients were taking them without full knowledge of how well the treatments worked.
This leads to a massive waste of money by other companies repeating the same research and going down the same dead-end streets that could have been avoided.
1.2.3 Trials Often Aren’t Representative of Real Patients
External validity is the extent to which the results can be generalized to a population of interest. The population of interest is usually defined as the people the intervention is intended to help.
Phase III clinical trials are designed to exclude a vast majority of the population of interest. In other words, the subjects of the drug trials are not representative of the prescribed recipients, once said drugs are approved. One investigation found that only 14.5% of patients with major depressive disorder fulfilled eligibility requirements for enrollment in an antidepressant efficacy trial.
As a result, the results of these trials are not necessarily generalizable to patients matching any of these criteria:
- Suffer from multiple mental health conditions (e.g. post-traumatic stress disorder, generalized anxiety disorder, bipolar disorder, etc.)
- Engage in drug or alcohol abuse
- Suffer from mild depression (Hamilton Rating Scale for Depression (HAM-D) score below the specified minimum)
- Use other psychotropic medications
These facts call into question the external validity of standard efficacy trials.
Furthermore, patient sample sizes are very small. The number of subjects per trial on average:
- 275 patients are sought per cardiovascular trial
- 20 patients per cancer trial
- 70 patients per depression trial
- 100 per diabetes trial

In the example above a drug is prescribed to millions of patients based on a study with only 36 subjects, where a representation of the general public is questionable.
Solution: Collect Data on Actual Patients
In the real world, no patient can be excluded. Even people with a history of drug or alcohol abuse, people on multiple medications, and people with multiple conditions must be treated. Only through the crowdsourcing of this research, would physicians have access to the true effectiveness rates and risks for their real-world patients.
The results of crowd-sourced studies would exhibit complete and utter external validity since the test subjects are identical to the population of interest.
Furthermore, self-trackers represent a massive pool of potential subjects dwarfing any traditional trial cohort. Diet tracking is the most arduous form of self-tracking. Yet, just one of the many available diet tracking apps, MyFitnessPal, has 30 million users.
Tracking any variable in isolation is nearly useless in that it cannot provide the causal which can be derived from combining data streams. Hence, this 30 million user cohort is a small fraction of the total possible stratifiable base.
1.3 Problems in Digital Health Innovation
1.2.1 $157 Billion Wasted on Duplication of Effort
There are more than 350,000 health apps. Mobile health app development costs $425,000 on average. Most of these have a ton of overlap in functionality representing $157,500,000,000 wasted on duplication of effort.
If this code was freely shared, everyone could build on what everyone else had done. Theoretically, this could increase the rate of progress by 350,000 times.

closed source competition vs open source collaboration
The obstacle has been the free-rider problem. Software Developers that open source their code give their closed-source competitors an unfair advantage. This increases their likelihood of bankruptcy even higher than the 90% failure rate they already faced.
How we Overcome the Free-Rider Problem
- Currently governments around the world are spending billions funding closed-source propriety health software. The Public Money Public Code initiative would require governments to recognize software as a public good and require that publicly-funded software be open source.
1.2.2 Isolated Data Silos
The best that isolated data on individual aspects of human health can do is tell us about the past. For example, dashboards telling us how many steps we got or how much sleep we got are known as “descriptive statistics”. However, by integrating all available data from individuals, similar populations, as well as existing clinical research findings and applying machine learning we may achieve “prescriptive” real-time decision support.
To facilitate data sharing, the we provide data providers with an onsite easily provisionable OAuth2 API server that will allow individuals to anonymously share their data with the global biobank.

Leave a Reply